Researchers at ZJU and the University of Sydney propose record-breaking text-to-image-to-text framework






The Generative Adversarial Network (GAN) has opened new frontier.
Researchers from Zhejiang University and the University of Sydney have proposed a novel global-local attentive and semantic-preserving text-to-image-to-text framework. This framework, called MirrorGAN, exploits the idea of learning text-to-image generation by redescription. It has improved semantic consistency between the text description and visual content and achieved the best results in the COCO and CUB datasets.

MirrorGAN is expected to empower the digitalization of cultural relics, adding vitality to ancient texts and bringing us closer to history.
Last year, NVIDIA's StyleGAN generated high-quality and visually realistic images. As an active research area in the field of natural language processing and computer vision, text-to-image (T2I) generation is conditioned on text descriptions rather than starting with noise alone.
Different T2I methods have been proposed to generate visually realistic and text-relevant images. However, using word-level attention alone does not ensure global semantic consistency due to the diversity between text and image modalities.
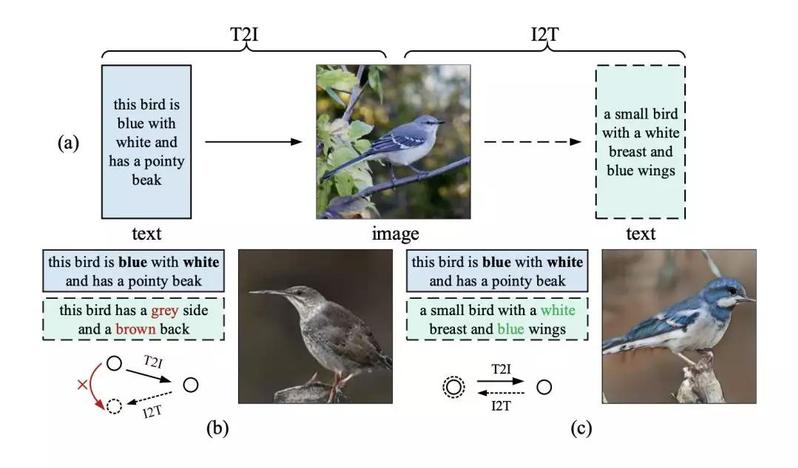
T2I generation can be regarded as the inverse problem of image captioning (or image-to-text generation, I2T), which generates a text description given an image. If an image generated by T2I is semantically consistent with a given text description, the generated image should act like a mirror that precisely reflects the underlying text semantics.
Motivated by this observation, MirrorGAN was proposed to improve T2I generation. MirrorGAN consists of three modules: a semantic text embedding module (STEM), a global-local collaborative attentive module for cascaded image generation (GLAM), and a semantic text regeneration and alignment module (STREAM).
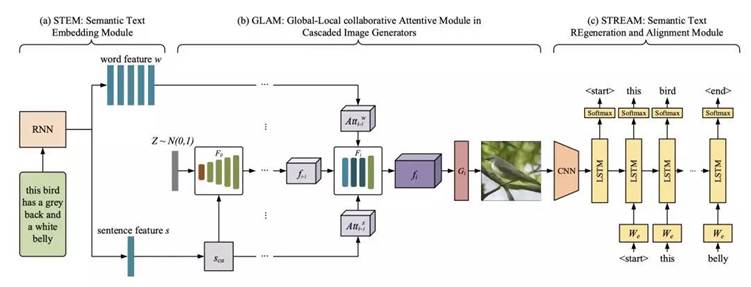
Researchers have also employed a text-semantics reconstruction loss based on cross-entropy (CE) to leverage the dual regulation of T2I and I2T. MirrorGAN displayed superiority with respect to both visual realism and semantic consistency in thorough experiments on two benchmark datasets.
This paper has been accepted by CVPR2019.
Edited by: XU Weiqin